Wednesday, 9. August 2006
MySQL macht's möglich: Nun gibt es auch von allen drei großen Datenbank-Anbietern freie Versionen ihres DBMS. Frei im Sinne von Lizenzgebühren. Frei aber nicht von verschiedensten Beschränkungen.
Welches freie Angebot welchen Unfreiheiten unterliegt, soll folgende Übersicht zeigen.
| DB2 Express-C | MySQL Pro | Oracle XE | SQL Server Express | | Betriebssystem | Linux, Windows | Linux, Windows, einige UNIX | Linux, Windows | natürlich nur Windows | | max. RAM-Größe | 4 GB | keine Begrenzung | 1 GB | 1 GB | | 32/64 Bit | 32/64 | 32 | 32 | 32 | | max. Anzahl Prozessoren | 2 CPU dual core | keine Begrenzung | 1 | 1 | | max. Größe einerDatenbank | keine Begrenzung | keine Begrenzung | 4 GB | 4 GB | | FreeProduction/ Redistribution | ja/ja | nein/nein (nur mit kommerzieller Lizenz) | ja/ja | ja/ja | | Support | Forum und/oder gegen Gebühr | Forum und/oder gegen Gebühr | nur Forum | nur mit Upgrade |
Offensichtlich sind die Spalten alphabetisch nach den Einträgen im Spalterkopf sortiert, oder ...
Na, welches FOSS DBMS sieht da am besten aus? Das ist doch einfach zu sehen:
Monday, 7. August 2006
Ted Codd mag zwar Anfang der 90er den Begriff OLAP (Online Analytical Processing) kreiert haben, aber er hat damit nicht die mehrdimensionale Speicherung und Analyse von Daten erfunden.
Dies geschah lange bevor Codds meinte, die Computerwelt mit seinen komischen 12 OLAP-Regeln beglücken zu müssen.
1998 schrieb Mark Hammond in der PC Week unter dem Titel "It's not Greek to me": OLAP has its roots in a multidimensional language called APL, developed in 1962, that used Greek symbols and ran on IBM mainframes.
Für einen APLer war und ist das Denken in und das Arbeiten mit multidimensionalen Strukturen selbstverständlich. Von daher haben wir den Hype um OLAP nie so recht verstanden. Wir hatten ja schon lange alles, was OLAP angeblich ausmacht, und noch vieles mehr.
Anbieter von OLAP-Software können noch viel von APL lernen. Nur die Speicherung von dünn besetzten Würfeln ist bei den meisten OLAP-Systemen effizienter gelöst.
Saturday, 5. August 2006
Nein, ich will nicht immer nur über böse Bubenstreiche der CW schreiben. Denn die meisten Artikel sind ok, informativ und sachlich. Es gibt auch auch die von der Sorte "fassungsloses Kopfschütteln". Bei manchen Fragen ist ein Redakteur mit technischen Details einfach überfordert und sucht und findet leider die falschen Ratgeber.
Ich habe also einige Ausgaben der CW mit dem Vorsatz gelesen, mal einen erwähnenswert guten Artikel zu finden. Und tatsächlich, ich wurde fündig:
" Microsoft umgarnt die Open-Source-Szene"
Anders als ein Kollege erinnert der Autor sich sehr wohl daran, wer unter dem Schafpelz steckt. Tatsächlich glaube ich nicht, dass die CW Microsoft-freundlich ist.
Es gibt aber leider diese bösen Unfälle.
Friday, 4. August 2006
Ich habe mich ja schon länger nicht mehr über die Computerwoche echauffiert. Obwohl ... in der heutigen Ausgabe gäbe es was, da hat mich so ein Gefühl von Bildzeitung überkommen. Dabei bleibt es dann aber auch.
Für so eine "saure Gurken"-Zeit habe ich noch einen Aufreger in Reserve.
Mai 2005 : Google beklagt sich über Microsoft
Es geht um den Schrott-IE, der in Version 7 als Suchmaschine MSN voreingestellt hat, was Google bitterlich beklagt. Aber man kennt ja Mickeysoft, sie versuchen es immer wieder.
Das kann mir ja eigentlich alles am ... vorbeigehen, denn ich verwende den IE nicht und habe auch in meinem Firefox Google voreingestellt. In meiner Welt ist zumindest das gut.
Außerdem: was schert mich der Krach zweier Monopolisten, sollen sie sich doch gegenseitig zerfleischen.
Interessant ist aber, was die CW aus der ganzen Sache macht. Man kann rein sachlich darüber berichten, mehr als eine Nachricht ist die Sache ja nicht wert.
Man kann aber auch Partei ergreifen, und das tut die CW: für Microsoft - als ob die es nötig hätten.
Thursday, 3. August 2006
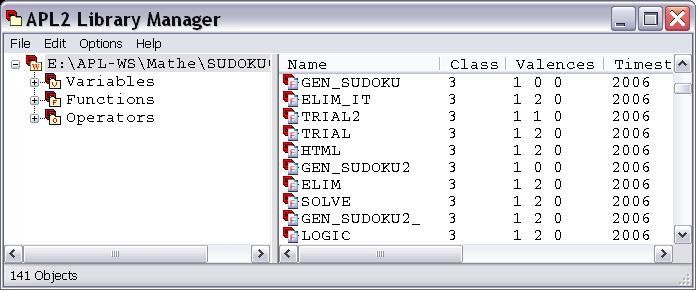
Das Highlight des letzten APL2 Release ( CSD 8) ist definitiv der APL2 Library Manager. Wieder ein Tool, das dem APL2 Workaholic viel Zeit spart. Es spricht für die sachliche Bescheidenheit der Entwickler, dass sie diese Erweiterung nur kurz und knapp aus einer rein technischen Perspektive beschreiben. Wer es lieber deutsch mag, schlage bei DPC nach.
Seitdem hat mir der APL2LM schon oft das APL2-Leben erleichtert.
 Ich habe tatsächlich verschiedene Versionen eine Workspaces vergleichen. Das ist an und für sich nichts Neues. Es gab ja schon vor dem APL2LM den 1 WSCOMP. Mit dem APL2LM muss ich dazu nicht extra eine Workspace laden.
Und hier liegt der eigentliche Gewinn, den ich durch den Library Manager habe. Wenn ich mal schnell in einem Workspace etwas nachschauen will, brauche ich diesen nicht mehr zu laden. Dazu stelle man sich folgendes vor:
Wednesday, 2. August 2006
APL und Virtuelle Maschine hat einen neue Bedeutung bekommen. Aber zuerst habe ich Bernd für diesen interessanten Tipp zu danken. Interessant und beachtenswert, oder gar mehr?
Wenn ich Virtuelle Maschine bis vor einigen Jahren gehört habe, dachte ich gerne an das gute alte IBM VM zurück. Ein Betriebssystem, auf dem man mehrere und verschiedene Mainframe-Betriebssysteme parallel fahren konnte. VM gaukelt den Gastsystemen ihre Hardware nur vor. VM ist inzwischen leider Geschichte, wie viele guten Dinge aus dem Hause IBM.
Daher ist VMware keine Erfindung der 90er. VMware macht unter Windows oder Linux das, was VM auf IBM Mainframes tat. Also keine neue Idee, nur eine andere Plattform, aber das alleine war schon eine gute Idee.
APL läuft natürlich unter beidem, VM und VMware, denn es gibt APL-Implementierungen für MVS, CMS, Windows und Linux (und viele mehr).
Dann gibt es da ja noch die berühmte Java Virtuelle Maschine, eine Erfindung der 90er. Die gaukelt niemanden was vor, zumindest keine Hardware. Die verschiedenen systemabhängigen JVM-Implementierungen gleichen aus Sicht des Java-Entwicklers plattformspezifische Unterschiede aus. Als Java-Programmierer produziere ich damit nur noch plattformunabhängigen Bytecode.
Dies ist auch die Idee hinter " Parrot": "Parrot is a virtual machine designed to efficiently compile and execute bytecode for interpreted languages" Und APL ist eben ganau solch eine interpretierte Sprache. APL ist sogar einer der ältesten Interpreter, nur etwas jünger als Basic. APL wird Ende November 40.
Doch zurück zu Parrot.
Tuesday, 1. August 2006
Es geschah vor nicht vor langer Zeit. Leider kenne ich den Fall nur aus Erzählungen, ich konnte aber das entsprechende Einladungsschreiben von Oracle Deutschland lesen.
Und das war starker Tobak, echt starker Tobak.
Anno 2001 verleibt sich IBM sich den Datenbankteil der Informix Corporation ein. Wie das bei solchen Übernahmen so ist, wurden Spekulationen über die Zukunft der übernommenen Datenbank angestellt. Bekannterweise hatte IBM zu diesem Zeitpunkt bereits eine Datenbank im Angebot.
Das war 2001. 2006, fünf Jahre später ist die Situation für Informix-Kunden inzwischen klar.
Aber die Freunde von Oracle Deutschland scheinen nicht zur schnellen Truppe zu gehören. Sie luden Jahre nach der Übernahme Informix-Kunden per Anschreiben und Hochglanzbroschüre zu einer Veranstaltung in Frankfurt ein. Hier sollte den "Verunsichterten" eine Perspektive in eine teurere Zukunft gegeben werden.
Dazu bemühte Oracle im Anschreiben anonyme Hilfstruppen:
Neutrale Beobachter des Datenbankmarktes würden davon ausgehen, dass IBM in zwei Jahren den Support für den Informix Dynamic Server aufgeben würde.
Leider lässt der Schreiberling die Identität dieser Researcher im Dunkeln. Das ist per se schon unseriös. Wenn an solch einer Aussage etwas dran ist, kann man doch ohne Problem Ross und Reiter nennen.
"Wer zu spät kommt" vollständig lesen
Monday, 24. July 2006
Dies ist das angekündigte Beispiel zur Aussage:
Die Anzahl der vorbelegten Felder eines Sudokus sagt wenig über die Beschwerlichkeit seines Lösungsweges aus.
Man nehme hierzu das zweite Sudoku in " Mit Muster". Wie man leicht zählt sind 28 Felder bereits vorgegeben, der Rest kann mit den einfachsten "logischen" Methoden gelöst werden. Der recht hohe SSbL-Score von 110 ("hard") ist ein Ergebnis der letztendlich spärlichen Vorbesetzung.
Und nun dies:
Gleiches Muster, gleiche Anzahl belegter Felder. Sollte doch ebenso einfach zu lösen sein.
Viel Spaß!
Auch ich habe meine " Kenner der Datenbankszene", die ich hier zu Wort kommen lasse.
Korrektur: nicht zu Wort, sondern zu Tabelle:
| | DB2 9 | Oracle10g R2 | MS SQL Server 2005 | | Best | Good | Good | | Best | Good | Worst | | Good | Best | Good | | Best | Good | Worst | | Good | Worst | Best | | Best | Good | Best | | Best | Good | Worst | | |
Zugegeben, die erste Spalte habe ich nicht mitgenommen. Hier stehen normalerweise Kategorien mit Datenbank-Eigenschaften, die in den folgenden Spalten pro DBMS wie zu sehen bewertet wurden.
Man kann dem Autor nicht unterstellen, dass er alles nur durch die blaue Brille sieht. Ich halte ihn daher für objektiver, also vertrauenswürdiger als anderer Leute " Kenner der Datenbankszene". Außerdem:
Sunday, 23. July 2006
Jeder, der Sudokus löst, kennt das. So wird gemeinhin beschrieben, wie beschwerlich der Weg zur Lösung eines Sudokus ist.
Doch Vorsicht, hier wird oft mit unterschiedlichem Maß gemessen.
Mein erstes Sudoku-Buch ("Sudoku", Fischer Taschenbuch Verlag) klassifizierte den Schwierigkeitsgrad gemäß der Anzahl der vorgegebenen Felder: 48, 32, 24, das war leicht, mittel und schwer. Ich halte diese Art der Einteilung für unangemessen. Denn man wird leicht Sudokus finden, die die gleiche Anzahl Vorbesetzungen haben, aber unterschiedlich "schwierig" zu lösen sind (ein Beispiel hierzu später).
Der " Sudoku Solver by Logic" nutzt zur Beurteilung der Lösbarkeit eines Sudokus schon nachvollziehbarere Kriterien: Es werden einige "logische" Methoden definiert, mit denen der menschliche Löser normalerweise ein Sudoku löst bzw. lösen kann. Diese Methoden sind unterschiedlich kompliziert in ihrer Anwendung, jede Methode erhält daher einen individuellen " Difficulty Score".
Zur Lösung eines Sudokus werden die einzelnen "logischen" Methoden mit unterschiedlicher Häufigkeit angewandt. Der "Score" für ein Sudoku ergibt sich aus der Summe der "Difficulty Score" aller angewandter Methoden, bei mehrfacher Anwendung geht " Difficulty Score" einer Methode entsprechend häufig in den "Score" ein.
Diesen "Score" eines Sudokus habe ich bereits "SSbL -Score" genannt und werde es auch weiterhin tun.
Thursday, 20. July 2006
Die zwei Sudokus, die täglich von einer hier nicht nennbaren Tageszeitung veröffentlich werden, fallen durch ihre symmetischen Muster auf. Z.B. solch eines:
Das Muster ist geklaut, das Sudoku habe ich mit nun fester Vorgabe einer Maske generieren lassen. Aufgrund dieses Musters erhielt das Rätsel einem ärmlichen SSbL-Score von 47 - "easy". Zu einfach.
Hier ein spartanischeres Muster, auch abgeschrieben aus besagter Zeitung, das Sudoku stammt aus meinem Generator:
Wednesday, 19. July 2006
Dieses Sudoku enthält nun keine systematischen Muster - hoffe ich:
... und so kam es zustande:
Das verbesserte erste Sudoku sah schon ganz gut aus, hat aber noch eine systematische Macke. Diese Macke ist kein Zufall, sondern jedes Sudoku, das wie beschrieben produziert wird hat diesen genetischen Fehler: In den Zeilen der mittleren Blöcke stehen stets "Drillinge".
Das liegt an zweierlei:
An der Vorgabe des Blocks oben links durch 9 9↑3 3⍴9?9. Allgemein gesprochen produziert TRIAL bei Vorgabe eines kompletten Blocks stets irgendwo diese "Drillinge".
TRIAL wählt die durchzutestenden Felder stets in gleicher Art und Weise aus, arbeitet die möglichen Lösungen für das gewählte Feld stets in gleicher Reihenfolge ab und beendet die Bearbeitung stets nach der ersten gefundenen Lösung. Kein Wunder, dass immer wieder die gleichen Muster auftauchen.
Beides kann einfach behoben werden.
Entweder verteile man die ersten 9 Vorgaben über alle 81 Felder:
9 9⍴((⍳81)∊9?81)\9?9
Oder man bearbeite die möglichen Lösungen einer Zelle in zufälliger Reihenfolge:
'RAN' TRIAL 9 9↑3 3⍴9?9
Der Parameter im linken Argument von TRIAL steht dabei - wie überraschend - für "random".
Oracle behebt mit dem aktuellen Patch alleine 23 Fehler in seiner Datenbank, 65 Bugs in allen Produkten. Die CW bezeichnet den aktuellen "Critical Patch Update" sinnigerweise als Patch-Fest.
Solche Feste kann man als Oracle DBA eigentlich nur mit viel Alkohol ertragen.
Apropos "behebt": Oracle-Kunden machen häufig die Erfahrung, dass Oracle-Patches neue Fehler produzieren. Dazu noch ein Zitat aus der erschütternden Dokumentation " Oracle hat ein Sicherheitsproblem": "Leider schleichen sich in die Updates aber immer wieder Fehler ein, so dass sich Anwender nicht hundertprozentig darauf verlassen können, ob ein Patch funktioniert und tatsächlich alle Schwachstellen wie erwartet beseitigt."
Tuesday, 18. July 2006
UNIQUE ist nicht die einzige Neuerung der Version 6.2. Da gibt es noch vier weitere bemerkenswerte Dinge:
⎕MOM-Objekte enthalten jetzt ⎕FX als Methode zur Erstellung einer Funktion in einem Objekt. So wird mit
mom_obj.⎕FX cr
die Zeichenmatrix cr zu einer Funktion innerhalb des Objekts mom_obj erhoben.
)OUTPUT wurde bereits mit Version 6.0 eingeführt und erhält in Version 6.2 mit STRICT eine weitere Option. Sowohl )OUTPUT ERROR als auch )OUTPUT STRICT sind sinnvoll, um nicht gewollte implizite Ausgaben in Funktionen aufzuspüren.
)OUTPUT STRICT ist eine Verfeinerung von )OUTPUT ERROR. Bei dieser Option wird nur dann ein "IMPLICIT OUTPUT" Error ausgeworfen, wenn eine sichtbare implizite Ausgabe produziert wurde. Die Fehlermeldung erscheint nach der Ausgabe.
|
 Ich habe tatsächlich verschiedene Versionen eine Workspaces vergleichen. Das ist an und für sich nichts Neues. Es gab ja schon vor dem APL2LM den 1 WSCOMP. Mit dem APL2LM muss ich dazu nicht extra eine Workspace laden.
Ich habe tatsächlich verschiedene Versionen eine Workspaces vergleichen. Das ist an und für sich nichts Neues. Es gab ja schon vor dem APL2LM den 1 WSCOMP. Mit dem APL2LM muss ich dazu nicht extra eine Workspace laden.
 ap127
ap127