Saturday, 27. May 2006
Letztes Jahr kaufte Oracle Innobase Oy, den Hersteller der Transaktions-Engine InnoDB. Das wäre eigentlich nichts Besonders, denn Oracle kauft seit einiger Zeit alles, was nicht niet- und nagelfest ist.
Das Besondere hier ist, dass MySQL InnoDB als Transaktions-Engine verwendet. Das macht den Kauf natürlich explosiv - für MySQL. Offensichtlich atmet inzwischen MySQL auf und durch, denn Oracle stimmte einer Verlängerung des dieses Jahr auslaufenden Vertrages zwischen MySQL und Innobase zu.
"... good news for MySQL customers and for the open source community" meint MySQL Vice President Zack Urlocker in seinem Blog.
Aber kann man Oracle tatsächlich trauen?
Wer Larry Ellison schon einmal tief in seine blauen Augen schauen konnte, der weiß ...
Tuesday, 9. May 2006
Stand-alone Data Mining Software kommt aus der Mode. Data Mining hört auf eine exklusive Tätigkeit von Elfenbeinturm-Analytikern zu sein. Schade und gut so.
Alle drei großen Datenbank-Hersteller haben in ihren Warehouse-Paketen Mining-Anwendungen gebundlet: Oracle seinen "Data Miner", IBM den "DB2 Intelligent Miner for Modelling and Scoring". Microsoft bietet seinen Data Analyzer als Mining Werkzeug an.
Aber hier beginnt das Problem: MS lizenziert den Analyzer und das Visualisierung-Werkzeug pro Windows Client. Das bedeutet, dass je mehr Anwender Mininganalysen ausführen wollen, desto teuer wird es für das Unternehmen.
Mining a la Microsoft ist und bleibt so eine esoterische Nischentätigkeit betrieben von verschrobenen Einzelkämpfern.
Dieses Preismodell macht das Microsoft Data Warehouse Softwarepaket letztendlich teurer als die vergleichbaren Angebote von IBM und Oracle.
Hier noch zwei Ergebnisse, die ich dem "2006 Enterprise Data Warehouse Software Survey" von Market Magic Research (Januar 2006) entnehme:
In " Was gibt's Neues in CSD8" habe ich folgende Erweiterung vergessen: - Windows XP themes will be recognized and used in all APL2 GUI windows. Tatsächlich habe ich das nicht übersehen oder gar vergessen, nein, viel schlimmer, ich habe die Weitergabe dieser Info unterdrückt. Denn bis heute wusste ich nicht, was das konkret bedeutet und wie ich eine Änderung erfahrbar machen kann.
Jetzt habe ich den Unterschied sichtbar machen können:
Alles klar?
Windows XP Themes können in den "Eigenschaften von Anzeige" (Microsoft deutsch) aktiviert, geändert und gespeichert werden.
Mit dieser Erweiterung sehen APL2 GUI "besser" aus. Das liegt sicher daran, dass sie sich besser in das "look" meiner anderen Desktop-Anwendungen einfügen.
Eine absolut sinnvolle Erweiterung und Schande über mein Haupt, dass ich sie vorher nicht auch nur eines Wortes gewürdigt habe.
Monday, 8. May 2006
Oh, du mein elektronisches Tagebuch. Ich habe einen neuen Auftrag für dich. Fungiere als Merkzettel für interessante Erkenntnisse, die nicht in die anderen Kategorien passen.
Hier der erste Eintrag:
Port- und Linereset!
Ein Zauberwort für die Telekom. Veranlasst bei Selbiger Verwirrung, aber auch zielgerichtete Aktivität.
Und in welcher Situation hilft das Zauberwort? Bei "Internet tot" und Telekom betreibt den Zugang.
Vielen Dank für den Tip!
Vista? Wer oder was ist Vista?
Das könnte mir ja eigentlich egal sein. Wenn die nächste Version von Windows gemeint sein sollte, wird es ja wohl noch etwas dauern, bis MS damit meint fertig zu sein. Dann beginnt erst der weltweite kostenpflichtige Testphase durch die Early Adaptors. Armes Völkchen!
Selbst das danach erscheinende SP1 wird mich dazu verleiten nach Vista upzugraden. Warum auch? Ich habe mich noch nie von SPs überzeugen lassen.
Aber man sollte stets mit der ordnungsgemäßen Planung deutscher Unternehmen rechnen. Es gibt doch tatsächlich Unternehmen, die Vista nach Verfügbarkeit ausrollen wollen, und das muss geplant sein. Das wirft dann folgende Frage auf:
Welche APL+Win Version läuft unter Vista.
Eine Frage an den Hersteller, hier zusammengefasst und ohne Gewähr die Antwort:
- die aktuelle Version 6.0 wird sicher unter Vista laufen
- Version 5.2 wurde schon frühzeitig unter Longhorn getestet
- bei Version 5.0 könnte man noch optimistisch sein
Alle Versionen vor 5.0 liegen mehr als 3 Jahre zurück, also teilweise noch vor XP. So gab es z.B. Probleme ⎕wi in APL+Win 3.0 unter 2000 und XP.
Ordnungsgemäß planende deutsche Unternehmen sollten also sehr alte APL+Win Versionen upgraden.
Das Leben kann ja so einfach sein:
Das beste DBMS wird es auch frei geben.
Auch auf die Gefahr hin, dass ich das schon mal hier geschrieben habe: Gleichzeitig mit der Verfügbarkeit von DB2 Viper als DB2 Version 9 etwa Mitte des Jahres wird Boris sie als Express-C zur Verfügung stellen.
Die zugrunde liegende Technologie wird die gleiche sein, keine Abstriche bei Express-C, also auch voller XML-Support. Für Entwickler das Tor zu einer besseren Welt.
Als Zeuge für diese Aussagen nominiere ich Boris Bialek, der muss es schließlich wissen.
Ich bete das nun schon seit Tagen, das ist fast schon ein Ceterum Censeo:
Die XML-Unterstützung durch DB2 Viper ist anders und besser als das, was Oracle, MS und auch DB2 V8.x hier zu bieten haben.
Ich habe in einer IBM-Publikation eine andere, präzisere Formulierung gefunden: Managing XML as data, instead of managing XML files/documents as content, is an opportunity for competitive advantage. In addition, DB2 Viper dramatically lowers business application development time, increases application performance and enables cost-effective use of XML data. Gut gebrüllt, Löwe.
Denn das ist der Casus Knaxus: XML wird als Datentyp behandelt und nicht als irgendetwas Fremdartiges, dass als LOB weggespeichert wird oder gar geshreddert ( zerrissen, zerschnitzelt, zerfetzt) wird. Das ist neu und einzigartig unter den großen Datenbankanbietern.
Don't cry, Oracle!
Sunday, 7. May 2006
Die XML-Integration in DB2 Viper scheint Oracle tatsächlich ernsthafte Probleme zu bereiten. Bisher war die Speicherung von XML-Dokumenten in einer Datenbank nur als Large Object oder in geshredderter Form möglich. Das eine bringt Nachteile in der Arbeit mit oder Suche nach Teilen von XML-Dokumenten, das andere bedeutet die stete Umwandlung einer hierarchischen Darstellung in eine relationale. Beides ist umständlich, "unnatürlich" und geht eindeutig zu Lasten der Performance.
Das war alles bisher eher halbherzig. Das wäre auch egal, wenn XML nur irgendein weiteres Datenformat wäre. XML hat sich aber in den letzten Jahren zu dem Standard für den Austausch von Daten gemausert. In diesem Zusammenhang ist auch interessant, was Boris Bialek zu Viper, XML und SOA schreibt.
Verständlich, dass Oracle nervös wird.
Kein Entwickler, der was auf sich hält, wird sich nicht dafür interessieren, wie ein notwendiges Feature implementiert ist. "It does matter", wenn es schlecht unterstützt, umständlich zu nutzen und auch noch unperformant ist.
Eigentlich könnten man ja solche Aussagen kommentarlos dorthin verfrachten, wo sie hingehören: in den Müll. Aber leider wirkt Oracles Propaganda bereits auf "Kenner der Datenbankszene".
Saturday, 6. May 2006
"Viper als Testversion verfügbar". So betitelte die Computerwoche in Ausgabe 15, 14.04.2006, auf Seite 8 einen kleinen Artikel, in dem die freie Verfügbarkeit der DB2 Viper für Beta-Tester angekündigt wurde. Kurz wird beschreiben, dass XML-Dokumente nativ verarbeitet werden können, sowohl mit SQL als auch mit XQuery.
Soweit so gut. Beim Lesen fallen so einige seltsame Formulierungen auf. Der Autor, Stefan Ueberhorst (ue) - immerhin Ressortleiter - , scheint nicht so recht zu wissen, was er schreibt. Offensichtlich ist er kein "Kenner der Datenbankszene". Muss er auch nicht. Also was macht er?
Richtig: Er holt sich Rat bei "Kennern der Datenbankszene". Und das sieht dann so aus: "Kenner der Datenbankszene sehen das kritischer: Microsoft erlaube in SQL Server 2005 ebenfalls die Indizierung von XML-Dateien, und Oracle habe XML-Datentypen bereits in Version 9i R2 eingeführt." Frei nach Karl Kraus: Diese Aussage ist so falsch, dass nicht einmal das Gegenteil wahr ist.
Ich meine hier nicht den kleinen grammatikalischen Fehler im Zitat, auch übersehe ich geflissentlich den Unsinn mit der Indizierung von XML-Dateien. Auch bei solch allerbesten Willen bleibt die obige Feststellung nicht nachvollziehbar.
... eine endlose Geschichte.
Mit dem quartalsweisen Critical Patch Update korrigiert Oracle 14 kritische Sicherheitslöcher in seiner Datenbank. Das ist nun keine neue Information und auch wohl eher Routine.
Eine seltsame Routine. Ist Oracle der einzige Datenbankhersteller, der solche Sicherheitsprobleme produziert? Oder bekommt Oracle auch hier nur die besondere Aufmerksamkeit der Computerwoche zu spüren.
Ersteres wird der Fall sein. Denn es ist bekannt, dass Oracle ein Qualitätsproblem hat. Das betrifft eben auch die Datenbank. Hier liegt Oracle eindeutig vor den Konkurrenten wie IBM oder Microsoft.
Laut Computerwoche bleiben mit diesem Patch einige Lücken noch sperrangelweit offen. Aber der nächste Patch kommt bestimmt.
Wer seine Oracle-Datenbank liebt, der patcht und patcht und ...
Bei Durchsuchen der Web-Seiten der Computerwoche habe ich folgende Aussage gefunden: "IBM kündigte die Vorstellung einer Vorabversion seiner neuen DB2-Generation Viper an, die XML-Dokumente speichern und indizieren kann. Mit der neuen Generation seiner Datenbank zielt IBM auf die Marktanteile seines Mitbewerbers Oracle ab und macht keinen Hel daraus, ihn damit aus dem Markt drängen zu wollen." Der erste Satz ist so richtig, dass man ihn nur unterstreichen kann. Zu dem zweiten Satz habe ich zwiespältige Gefühle:
1. Gut so, weg mit Oracle, in die Wüste mit Larry.
2. Mein Rechtschreibhilfe meckert bei "Hel". Ich kann nichts dafür, das ist ein Zitat, das war schon so falsch.
3. Dieser Satz ist so trivial im Sinne von selbstverständlich, dass er die Druckerschwärze oder die IP-Kosten nicht wert ist.
Wozu würde IBM sonst eine neue Version von DB2 herausbringen, natürlich, um seinen Marktanteil zu steigern. Und das geht am besten auf Kosten von Oracle. IBM ist doch wie Oracle, MS oder andere kein Knabenchor, da hätten die Aktionäre Einiges dagegen.
Werden die Redakteure der Computerwoche nach "Anzahl geschriebener Buchstaben" bezahlt (wenn dem so ist, hätte ich zumindest Hehl mit zwei "h" geschrieben). Manchmal habe ich schon den Verdacht.
Dazu demnächst mehr auf diesem Kanal.
Das waren die guten Nachrichten über "IN". Kann ich also meine korrigierte Variante von "IN" durch die offizielle Version ersetzen? Das wäre erstrebenswert, geht aber nicht. Denn ich habe noch zwei weitere Dinge "verbessert" - verbessert im Sinne der Verwendung von "IN" in meinem APL-Workspace Crawler.
Das INen von großen geschachtelten Variablen kann sehr lange dauern und während dieser Zeit die kompletten CPU-Ressourcen in Anspruch nehmen. Dies kann nicht direkt IN oder )IN angelastet werden, denn der eigentliche Übeltäter ist ⎕TF.
Hierzu ein Beispiel: Auf meinem neuen 2 GHz Rechner dauert das Inen einer 10553x24-Matrix der Tiefe 2 ca. 20 Minuten. Die Größe der Variable ist, gemessen mit "4 ⎕AT", 9.117.824 bzw. 1.744.766. Die Größe der ATF-Datei, die ausschließlich die Variablen enthält ist, ca. 2MB.
Für den meinen Crawler, der sowieso nur nach Funktionen und Operatoren sucht, war das pure Zeit- und Ressourcenverschwendung. Ich habe mir daher die Definition von IN vorgenommen und entsprechend geändert: Hast du gerade eine Variable zur Bearbeitung vor dir, dann gehe zum nächsten Objekt. Einfach und effizient!
Wäre das nicht auch ein Feature für die offizielle Version von "IN". Auch dem APL2 Library Manager würde es gut zu Gesicht stehen: Der Anwender wird vor dem Einlesen komplexer APL2-Variablen aus ATF-Dateien erst mal gefragt, ob er sie wirklich sehen will - oder ähnlich.
Thursday, 4. May 2006
Es gibt schon nette Zufälle. Da habe ich mich in einem Vortrag darüber beklagt, dass die externe Funktion "IN" ('FILE' 11 ⎕NA) nicht kompatibel zum Kommando )IN ist. Und keine Stunde später sind zumindest zwei meiner Vorschläge bereits umgesetzt.
Naja, nicht mal ein APL-Entwicklungsteam arbeitet so schnell, obwohl die sonst schon sehr schnell reagieren.
Die wahre Geschichte ist folgende: Ich war eben nicht der Einzige, der Stress mit "IN" hatte. David bekam die gleichen Probleme, als er "IN" für seinen Library Manager einsetzte. Als Entwickler war es für ihn ein leichtes, eine verbesserte Version von "IN" zu erstellen oder anzufordern. Ich habe nur meine eigene, inoffizielle korrigierte Variante.
Diese Änderungen blieben aber undokumentiert. In der Liste der "Enhancements Added" zur CSD8 fehlen entsprechende Einträge, der User's Guide ist hier - "Supplied Workspaces/FILE Workspace/Transfer Group" - ohne Änderung.
Und das ist neu: IN '99 ATFNAME'
IN '''e:\temp temp\name.atf'''
Bis zur CSD8 haben die Leerstellen "IN" zur vorzeitigen Aufgabe gezwungen - zur erkennen am Ergebnis 0.
Tuesday, 2. May 2006
Alles Jahre wieder gibt es eine Neue Version von APL+Win. Vor zwei Jahren war es Version 5.0, letztes Jahr 5.2 und nun 6.0. Nicht so richtig konsequent, was die Zählweise betrifft. Aber egal.
Das Highlight der 6.0 ist offensichtlich das neue, kolossale Dateisystem. Von der Struktur her arbeitet das "Colossal Filesystem" genauso wie das allseits bekannte und beliebte Komponenten-Dateisystem, nur viel schneller. Ich habe im Januar Messungen gesehen, die in Extrem-Situationen eine 1000fache Verbesserung brachten.
So oder auch weniger, sicher ist, es ist auf jeden Fall tierisch schnell.
Mit den CFS fällt auch die 2GB-Grenze für die Größe der Datei. Das war auch inzwischen nötig. Wer also viel mit Komponenten-Dateisystemen arbeitet, wird mit neuen System viel Freude haben.
Interessant ist auch die TRY-CATCH-Kontrollstruktur. Java-Entwicklern wohl bekannt, kann sie zur besseren Strukturierung von APL-Code führen. Auf jeden Fall macht sie das Error-Handling explizierter als es mit ⎕elx möglich ist.
"APL+Win 6.0 ist da" vollständig lesen
Monday, 1. May 2006
... in CSD8? Kurz geantwortet:
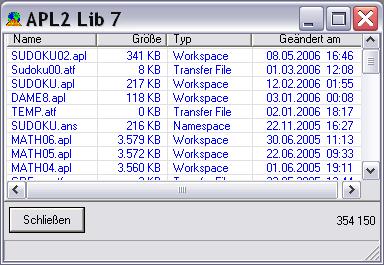
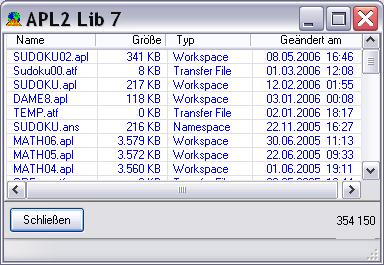
 Den APL2 Library Manager:
Ein Werkzeug zum durchforsten von APL2 Workspaces in allen drei Dateiformaten: .APL, .ATF und .ANS. Der APL2LM erspart es mir z.B. das Laden eines Arbeitsbereiches, um dort etwas zu suchen oder anzusehen. Es sieht aus, als ob der APL2LM ein sehr nützliches Werkzeug werden könnte!
Über eine weitere Neuerung habe ich bereits geschrieben: "Calls to APL2", das Arbeiten mit Slave-Interpretern direkt aus einer APL2 Sitzung heraus. Dazu wurden gleich zwei Dinge zum APL2 System hinzugefügt, die externe Funktion APL2PIA und der Hilfsprozessor 200. Der APL2 Library Manager macht reichlich Gebrauch von APL2PIA.
Es gibt noch viele "kleinere" Erweiterungen:
|

 ap127
ap127