Thursday, 22. March 2007
Die Zeit ist reif für den Data Mining-Sommer. Nein, kein Frühling (den hatten wir bereits), auch kein zweiter Frühling (wo war der Sommer dazwischen?), sondern Sommer. Die Gründe für diesen Optimismus wurden auf der CeBIT von der Expertenrunde unter dem Titel " Zweiter Frühling für Data-Mining?" mehr oder weniger deutlich herausgearbeitet.
- Data Mining ist als Disziplin gereift. Es liegt reichlich Erfahrung in unterschiedlichsten Anwendungsbereichen vor. Inzwischen verlassen auch mehr und mehr ausgebildete Data Mining Spezialisten die Universitäten.
- Data Mining Software ist erschwinglich. Nicht billig oder gar kostenlos, aber bei weitem nicht mehr so teuer wie noch vor einigen Jahren.
Man sollte jedoch vorsichtig sein: Nicht jede Data Mining-Aufgabe ist mit jeder x-beliebigen DM-Suite zufriedenstellend zu bewältigen. Je mehr unterschiedliche Algorithmen angeboten werden, desto bessere Ergebnisse können erzielt werden. Je mehr Data Mining als Prozess von der Daten-Akquisition bis zur Darstellung der Ergebnisse mit der jeweiligen Software implementiert werden kann, desto direkter sind die Ergebnisse nutzbar.
Wednesday, 21. March 2007
MS Access wird gern als Prototyping-Werkzeug oder als Umgebung für die schnelle Entwicklung von Datenbankanwendungen unter Windows genutzt. Aber oft bleibt es nicht beim Prototyp und die schnell entwickelte Einzelplatzanwendung hat urplötzlich viele Nutzer. Wenn einem dann die Anwendung um die Ohren fliegt, erfährt man, dass Access keine solides Basis für skalierbare Anwendungen bietet.
Das gilt vor allem für die einer Access-Anwendung zugrunde liegenden Datentabellen, soweit sie in der Jet-Engine verwaltet werden. Je größer die benötigten Tabellen, je mehr darauf zugreifende Nutzer, desto notwendiger wird ein Wechsel auf eine solide Datenbank.
Wenn es nach Microsoft ginge, führte der Upsizing-Pfad geradewegs zum SQL Server. Es gibt aber bessere Alternativen, die MS natürlich nicht mit einem Upsizing-Agenten (Extras/Datenbank Dienstprogramme) unterstützt. Trotzdem ist eine Migration der Daten nach DB2 mittels ODBC oder OLE DB eine einfache, gut automatisierbare Aufgabe. Die wesentlichen Schritte werden bestens in " Migrating a Microsoft Access 2000 Database to IBM DB2 Universal Database 7.2" beschrieben. Auch wenn "2000" und "7.2" nicht gerade up-to-date klingt, es funktioniert auch mit aktuelleren Versionen.
Sunday, 18. March 2007
Was sind wohl die Kosten, die ein Unternehmen für Data Mining Software kalkulieren muss. Die Antwort von Kennern der Data Mining-Szene: Data Mining gibt es bereits für lau, denn entweder kommt es im Bundle mit Datenbank-Software, oder es kommt als Open Source. Open Source scheint immer noch ein Synonym für kostenlos zu sein. Das alles ist ein großer Irrtum und dazu noch gefährlich.
An dieser Erkenntnis durfte ich am Freitag als Zuhörer einer Diskussion unter dem Titel "Zweiter Frühling für Data-Mining?" auf der CeBIT teilhaben. Sie wurden von den ausgewiesenen Data Mining Experten Wolfgang Martin und Peter Gentzsch zum Besten gegeben. Auch wenn beide viel Richtiges, aber auch nicht viel Neues zur Diskussion beitrugen, halte ich diese Einschätzung zu den Kosten von DM-Software für ziemlich daneben.
Denn das Martinsche Argument, dass DM-Software eingeschweißt in Datenbank-Pakete nichts oder nur wenig kostet ist nichts anderes als Schönrechnerei. Er meinte damit wohl die BI-Suites von IBM oder Microsoft. Offensichtlich wird Data Mining durch solche Bundles günstiger. Doch wie man es auch rechnet, die Kosten bewegen sich pro Prozessor komfortabel im fünfstelligen Bereich. Man sehe sich hierzu im Vergleich die reinen Kosten für die Datenbanken DB2 oder MS SQL Server an.
"Data Mining für lau?" vollständig lesen
Monday, 19. February 2007
Abstürzende Software ist ärgerlich. Aber das kommt selbst bei den besten Exemplaren dieser Spezies vor. Keine einigermaßen komplexe Anwendung ist fehlerfrei - solange Menschen ihre Finger im Spiel haben. Irren ist eben menschlich. Ich bin gespannt, wann wir endlich in der Lage sind, die Fehlerfreiheit von Programmen maschinell nachzuweisen.
Solange das nicht möglich ist, müssen wir mit allzu menschlichen Fehlern leben. Selbst APL ist davor nicht gefeit. Gerade beim Test neuer Features bringe ich ab und zu eine APL-Sitzung zum Absturz. Es passiert auch schon mal, dass ich durch wochenlange intensive Entwicklung einer APL2-Anwendung den dazugehörigen Workspace zerraspelt vorfinde. Aber stets hilft hier die )clear- )copy - )save - Sequenz.
Das alles kommt so selten vor, dass man getrost APL-Systeme als äußerst zuverlässig und stabil bezeichnen kann.
Auch gängige Anforderungen an die Kompatibilität innerhalb der APL-Versionen eines Herstellers werden zufriedenstellend erfüllt. Selbst eine Migration von APL-Anwendungen auf Vorversionen ist mit den üblichen Einschränkungen möglich.
Ganz anders bei MS Access. Ich habe selten eine Anwendung so schnell wegen simpelster Probleme komplett abstürzen sehen. Es genügte schon, eine mdb mit einem ins leere gehenden Verweis zu übernehmen. Auch bei der Aufwärtskompatibilität von Version 10 nach 11 liegt offensichtlich einiges im Argen.
Ich will nicht wissen, wie viele Entwickler bei Kleinstweich an Access rumentwickeln, es werden garantiert mehr sein als alle Entwickler von APL-Systemen zusammengenommen. Ich kann mich des Eindrucks nicht erwehren, dass in den vorliegenden Fällen die Softwarequalität umgekehrt proportional zur Größe der Programmierteams ist.
Sunday, 18. February 2007
Bisher stand Data Mining nur für einen kleinen Kreis von Experten offen. Das wird sich ändern. Seit einiger Zeit arbeiten verschiedene Hersteller von Data Mining-Suites daran, diese Analyse-Software einem größeren Anwenderkreis zu öffnen. Am besten allen möglichen Anwendern - zumindest in jedem Unternehmen: " Data Mining for the masses".
Glücklicherweise gehörte ich auch zu dem erlauchten Kreis von Auserwählten, die Data Mining-Software auf ihrem Rechner installieren und nutzen konnten. Das waren und sind recht teure Einzelplatzlösungen, die -wenn überhaupt - nur durch sehr viel mühsame API-Programmierung einem größerem Kreis von Anwendern zugänglich gemacht werden konnten.
Die DB2 Data Warehouse Edition und hier insbesondere die Miningblox machen dem ein grausames Ende. Sie zerren Data Mining aus den Elfenbeintürmen der Analytiker und machen es für die staunenden Massen nutzbar. Und da die Miningblox auf einem Web Application Server laufen, also eine einfacher Browser als Frontend fungiert, sind dies nicht nur die Massen a la Microsoft - Systemvoraussetzung MS Windows -, sondern es kann wahrlich jedermann / jederfrau Mining-Analysen durchführen.
Sunday, 11. February 2007
Von "Multi-row Fetch" oder "Multi-row Insert" hatte ich bisher nichts gehört, bis mich David fragte mich heute morgen danach fragte. Ein APL2-Fan wünscht sich wohl, dass der AP127 diese DB2-Features nutzt. Recht hat er.
Seit der Version 8 bietet die Programmierschnittstelle der DB2 für z/OS die Möglichkeit, mit nur einem Fetch auf mehr als nur eine Zeile des Resultsets zuzugreifen. Eine sehr sinnvolle Erweiterung, die mit der Version 8.2 dann auch für andere DB2-Plattformen zur Verfügung gestellt wurde. Es liegt wohl nur an der Beschränkheit der Mainstream-Programmiersprachen, dass obwohl ein SQL-Select eine Menge von Tabellenzeilen als Ergebnis ergibt, aber auf Elemente dieser Menge nur einzeln zugegriffen werden kann - Zeile nach Zeile per Schleife.
Für APL mit seiner hervorragenden Fähigkeit, komplette Datenstrukturen verarbeiten zu können, stellt diese Einschränkung eher einen ärgerlichen Logikbruch dar. Nur gut, dass mit dem AP127 per Parameter für den Fetch mehrere Ergebniszeilen mit einer Anweisung zum APL2 übertragen werden können.
"Das passt" vollständig lesen
Saturday, 10. February 2007
Wer wagt, der gewinnt nicht immer. Ich habe es immerhin versucht und habe erfahren:
Die Minimalvoraussetzungen für die Installationen der Datawarehouse Edition auf einem Rechner sollte man nicht drastisch unterschreiten. Bei zu wenig RAM legt sich nach erfolgter Installation die Konfiguration der DWE-Komponenten schlafen. Der Versuch den WAS zu starten stößt an die Grenzen des physikalischen Arbeitsspeichers.
Der DWE 9.1.1 Installation Guide verrät unter "Installation Requirements" die Hardware-Anforderungen der DWE-Komponenten:
Sunday, 4. February 2007
Nach dem ich mich schon hinreichend über die neuen Algorithmen für das Data Mining in der Data Warehouse Edition gefreut habe, gibt es mit den "Miningblox" als weitere herausragenden Neuerung einen weiteren Anlass zu froher Erwartung.
"Miningblox: Miningblox tags extend Alphablox functionality with data mining. IBM provides a toolkit and a framework for BI developers so they can easily create custom mining solutions for their business users by using Web applications. The complexity of mining is hidden behind a common Web interface that empowers business users to use data mining without needing to install a database on their own systems."
Mit Miningblox wird also die Erstellung von Data Mining-Anwendungen erleichtert, die auf einem Application Server unternehmensweit zur Verfügung gestellt werden können. Das klingt nach wahrhaftigem "Data Mining for the masses", keine komplexen Software-Installationen auf allen Rechnern, die auf Mining-Analysen zugreifen sollen. Als Frontend genügt ein Browser.
Die Mining-Analysen laufen weiterhin in der Datenbank, hier unter Kontrolle eines Application Servers, der mittels Alphablox die Mining-Ergebnisse dem Anwender zur Verfügung stellt.
Aber bis dahin muss ich noch einige Steine aus dem Weg räumen:
"On the DWE WebSphere application server, you must manually deploy the Miningblox Framework. For more information, see the file readme.txt in the \mbx\install directory." (Miningblox: Administration and Programming Guide, S.5)
Das klingt nach zusätzlicher Arbeit.
Saturday, 3. February 2007
Man sollte nie ungeprüft glauben, was von der Journalie schwarz auf weiß zu Papier gebracht wurde. Und wenn's im Internet erscheint, wird es nicht glaubwürdiger.
So las ich gestern auf der Titelseite eines Kölner Boulevardblattes, dass Felix Magarth die Nachfolge von Thomas Doll beim abstiegsgefährdeten HSV antreten würde. Abends war klar, dass Magarth das Angebot des Vereins abgelehnt hatte. Eine gesunde Skepsis ist also bei allem Gedruckten angebracht.
Wie auch bei folgendem, vordergründig unverfänglichen Artikel in der Computerwoche mit dem Titel " Portale: Microsoft vor IBM und SAP". Hier wurden die Ergebnisse eines Vergleichs der Portal-Angebote von IBM, Microsoft und SAP dargestellt.
Der Artikel macht auf den ersten Blick einen ordentlichen Eindruck, eines seriösen, unabhängigen Blattes wie der Computerwoche würdig. Gut möglich, dass in Sachen Portal die neue MS Sharepoint Server-Version (Beta 2) bereits knapp die Nase vorn hat vor IBMs Webshere Portal 6.0 und weit vor dem SAP Enterprise Portal. Das wäre tatsächlich eine kleine Überraschung, da Microsoft bisher im Portal-Markt keine führende Rolle gespielt hat.
Friday, 26. January 2007
Die Empfehlung, alle Design Studio Workspaces von DWE 9.1 nach 9.1.1 zu migrieren macht schon Sinn. Auch wenn ich bisher fast ohne Probleme 9.1 Workspaces öffnen konnte, häufen sich nun Meldungen über Inkompatibiliäten.
Tatsächlich habe ich bisher in den mit 9.1 erstellten Projekten keine Änderungen vorgenommen, die ich hätte speichern wollen oder müssen. Ich bin also bisher gut ohne Speichern oder auch das angemahnte Migrieren von Projekten ausgekommen.
Es war schon irritierend, das im Datenbank-Explorer immer noch Verbindungen mit Datenbanken der DB2-Version 8.2 gelistet wurden, obwohl ich diese längst nach DB2 9.1 migriert hatte. Aber diese Kleinigkeit lässt sich durch ein wenig Handarbeit bereinigen.
 Die Meldungen "Fehler beim Speichern" allerdings, die bei Änderungen an Mining-Flows erscheinen, sind nun der mehr oder weniger freundliche Hinweise, sich der letzten verbliebenen Nach-Installationsaufgabe zu widmen:
"Migrating Design Studio workspace projects from DWE 9.1 to DWE 9.1.1"
Einfach unter "Datei" "Arbeitsbereich wechseln ..." auswählen und in der folgenden Eingabeaufforderung das Stammverzeichnis für den neu anzulegenden Workspace eintragen. Danach wird das Design Studio mit dem neuen Arbeitsbereich gestartet.
Thursday, 25. January 2007
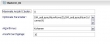
Der "mittelpunktbasierte" Clusteralgorithmus mit einer Kohonen-Karte lässt sich durch verschiedene Parameter beeinflussen. In den Mining-Einstellungen des Clusterer-Operators wird nach Auswahl von "Kohonen" als Algorithmus "Anzahl Durchgänge" angeboten. Die maximale Anzahl Cluster ist als Vorgabe für beide Segementierungsverfahren vorgesehen.
Bleiben noch die beiden Größen für die Bestimmung des "Zuordnungslayout": LayoutNumRows und LayoutNumColumns. Hierfür bietet der Clusterer-Operator keine eigenen Eingabefelder an. Es bleibt also nur die Spezifikation der Layoutwerte mittels "Optionale Parameter".
Und das ist nicht trivial, da sollte man schon mal die Online-Hilfe zu Rate ziehen. Die rät einem mehr oder weniger verklausoliert zu
DM_setAlgorithm('Kohonen','<LayoutNumRows>4</LayoutNumRows><LayoutNumColumns>5</LayoutNumColumns>').
Zumindest habe ich keine bessere Variante gefunden.
Sunday, 21. January 2007
Nach nun mehr als 30 Jahren ergab sich die Gelegenheit, mich wieder intensiver mit den Grundlagen der Mathematik zu beschäftigen. Der Mathe-Kurs für Informatiker im ersten Semester erinnert natürlich sehr an des 1.Semester eines Mathematikers: Mengenlehre, ein wenig Algebra, schon mehr Lineare Algebra und natürlich die Anfänge der Analysis.
Für mich ist das mehr als nur eine Wiederholung. Lineare Algebra macht mir heute wesentlich mehr Spaß als zu Beginn meines Studiums. Das gleiche gilt für die Algebra. Meine Zuneigung zu ihr habe ich ja erst im Hauptstudium entdeckt. Dazu war der richtige "Lehrer" nötig.
Heute ist es für mich wesentlich einfacher, mathematische Probleme zu lösen. Das liegt nicht nur daran, dass ich eine komplette Mathe-Ausbildung genossen habe. Ich habe auch noch APL zur Unterstütztung. Die öde Rechnerei zu Fuß ist passe. So ist das Produkt von Matrizen mit der Eingabe von nur fünf Zeichen zu berechnen, die Inverse benötigt gar nur zwei. Und das ohne jegliche eigene Programmierung.
Ebenso wenig stellt die Berechnung von Eigenwerten und -vektoren eine zeitraubende Aufgabe dar. APL hilft dem Mathematiker sich mit den wesentlichen Dingen zu beschäftigen.
"Das muss mal geschrieben werden" vollständig lesen
Saturday, 20. January 2007
Neural Networks are back!
"Kohonen Clustering: The Clusterer operator now provides the neural Kohonen Clustering algorithm." Dies ist ja eigentlich kein neuer Algorithmus: Das Clustern mit der Kohonen Karte kannte schon der gute, alte Intelligent Miner for Data. Ich habe dieses Verfahren oft als Alternative zur demographischen Segmentierung benutzt, die jeweils gebildeten Gruppen verglichen und mich dann doch meistens für das Ergebnis des demographischen Algorithmus entschieden.
Aber eben nur meistens. Es kann nicht falsch sein, zu einer Mining-Aufgabe verschiedene Verfahren zur Verfügung zu haben. So kann man sich einen besseren Überblick über das Problemfeld verschaffen.
Ich habe als Alternative zu einer Baumklassifikation, die die vor einigen Wochen erstellt hatte, testweise eine Naive Bayes-Klassifikation durchgeführt. In diesem Falle war ich mit dem neuen Ergebnis nicht sonderlich zufrieden, obwohl der Visualizer durchweg bessere Qualitätswerte ausweist. Denn die im Feldbedeutungsdiagramm angegebenen Einflüsse der Variablen waren und sind im Falle der Baumklassifikation realistischer.
Friday, 19. January 2007
Und nun zum Höhepunkt des DWE Refresh - zumindest aus meiner Sicht: die neuen " Data mining features". Ich meine damit nicht, dass die anderen Neuerungen marginal sind. Im Gegenteil, schon alleine die bisher beschriebenen Erweiterungen sind mehr als ich von einem "Refresh" erwarte. Von einem hunderstel Upgrade kann man höchstens etwas mehr als nur Fehlerkorrekturen erwarten.
Neue Mining-Algorithmen berechtigen eigentlich zu mehr als nur einem Hunderstel, z.B. zu 9.2 oder 9.5 oder gar zu 10.0. Dieses Refresh bring für mich mehr als eine komplette neue Windows-Version. Vista bringt die Menschheit nicht voran, wenn man mal von Intel oder AMD absieht. Lieber ein neuer Mining-Algorithmus als Tausend angeblicher Verbesserungen am GUI. MS ist doch inzwischen mehr damit beschäftigt, selbst aufgerissene Löcher zu stopfen als wirkliche Innovationen zu auszuliefern.
Aber das ist ein weites Feld. Ich komme lieber zurück zu den wichtigen und interessanten Dingen im IT-Leben, hier zu der Naive Bayes Klassifikation in der Data Warehouse Edition:
"Naive Bayes classification: The classification of information that is gathered from non-structured documents is a key element of structured and unstructured mining analysis. This algorithm provides this functionality with best acceptance throughout the industry. Naive Bayes classification is supported in the predictor operator."
Das ist eine Bereicherung für die Vorhersage kategorialer Variablen. Hier gab es bisher nur die Baum-Klassifikation, während zur Vorhersage kontinuierlicher Attribute sich gleich drei Verfahren anbieten. Es ist immer gut, eine Alternative zu haben. Trotz "naiver" Unabhängigkeitsannahmen liefert Naive Bayes häufig gute Ergebnisse.
Das ist aber noch nicht alles:
Friday, 12. January 2007
Handelt es sich bei den Microsoft Agents tatsächlich um eine ausgereifte Technologie?
Es soll wohl eine "Technologie" sein, aber auch nicht mehr:
"This is because Microsoft Agent, by itself, is really just a software technology rather than a complete, integral software application that automatically does something." Es ist scheinbar eine "ausgereifte" Technologie, da sich seit 2003 hier offensichtlich nichts mehr getan hat.
Der Link " Microsoft Agent in the MSDN Library" auf "Microsoft Agent Home" führt inzwischen sogar ins Leere. Handelt es sich möglicherweise um eine vergessene Technologie?
Vielleicht hat Mickeysoft seine Agenten vergessen, das Web vergisst nichts so schnell. Die MS Agents haben sogar einen Eintrag bei Wikipedia. Diese Seite ist erheblich aktueller als das Agentenheim.
Ebenso up-to-date ist der " Microsoft Agent Ring". Für Leute, die sich mit Mickeysofts vier "characters" nicht zufrieden geben können, gibt es hier viel Material zum Downloaden.
|
 Bleiben noch die beiden Größen für die Bestimmung des "Zuordnungslayout": LayoutNumRows und LayoutNumColumns. Hierfür bietet der Clusterer-Operator keine eigenen Eingabefelder an. Es bleibt also nur die Spezifikation der Layoutwerte mittels "Optionale Parameter".
Bleiben noch die beiden Größen für die Bestimmung des "Zuordnungslayout": LayoutNumRows und LayoutNumColumns. Hierfür bietet der Clusterer-Operator keine eigenen Eingabefelder an. Es bleibt also nur die Spezifikation der Layoutwerte mittels "Optionale Parameter".
 ap127
ap127